GBAITA 数字经济发展研究中心
总监:车品觉
专家作者:高璇颖
在2024年的科技界,一个全新的里程碑诞生了。OpenAI的o1系列大语言模型的发布,不仅标志着人工智能在逻辑推理和问题解决方面的巨大飞跃,也预示着人类对机器智能的理解和应用将进入一个全新的阶段。o1模型以其卓越的性能,在数学、编程和科学领域展现了超越过往模型的能力,这得益于其独特的“思维链”(Chain of Thought)技术和自我对弈强化学习方法(Self-Play RL)。本文将深入探讨o1模型的技术特性、如何模拟人类的思维过程,以及o1模型对未来AI发展趋势的影响,探讨其如何推动AI技术向更高级别的推理能力迈进。
一、 模型发布:OpenAI发布o1大模型,在数学、编程等专业科学领域性能强大
2024年9月13日,OpenAI正式发布了备受期待的o1系列大语言模型,之所以o1命名,据OpenAI首席研究官鲍勃·麦格鲁(Bob McGrew)透露, “o1”这个名字是为了“将计数器重置为1”,并称“我认为我们传统上在命名方面很糟糕,所以我希望这是更明智、更清晰地向世界传达我们在做什么的第一步。” OpenAI 创始人山姆·奥特曼(Sam Altman) 将 o1 称为“迄今为止最强大、最一致的系列模型”, 这预示着o1模型将成为OpenAI一系列推理模型中的新起点。
o1系列分包含三款模型,OpenAI o1、OpenAI o1-preview和OpenAI o1-mini。OpenAI o1是高级推理模型,暂不对外开放。OpenAI o1-preview,更注重深度推理处理,每周可使用30次。OpenAI o1-min,这个版本更高效、划算,适用于编码任务,每周可使用50次。
该模型凭借强大的推理能力,在科学、数学和编程领域的推理深度和准确性上表现出色,超越了以往GPT系列模型。
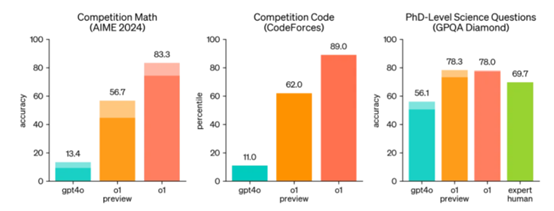
o1 在具有挑战性的推理基准测试中显著优于 GPT-4o
为了突出相对于 GPT-4o 的推理性能改进,OpenAI 在一系列不同的人类考试和机器学习基准测试中对o1 模型进行对比测试。实验结果表明,在绝大多数推理任务中,o1 的表现明显优于 GPT-4o。
在解决数学问题上,o1模型能力具有显著提升。在国际数学奥林匹克(IMO)资格考试中,GPT-4o 仅正确解答了 13% 的问题,而 o1 模型正确解答了 83% 的问题。
在2024年的AIME美国高中生数学竞赛中,o1模型的表现令人瞩目。相比之下,GPT-4o模型平均仅正确解答了12%的问题(1.8/15)。而o1模型在面对每个问题仅有一个样本的情况下,正确解答率达到了74%(11.1/15)。当样本数量增加到64个,并且模型在这些样本上达成一致时,正确率提升至83%(12.5/15)。更令人印象深刻的是,当使用学习到的评分函数对1000个样本进行重新排序后,o1模型的正确率达到了93%(13.9/15)。这一得分足以让o1模型在全美排名中跻身前500名,并超过了美国数学奥林匹克竞赛的分数线。
同时,OpenAI 对其 o1 模型在 GPQA Diamond 基准上进行评估,该测试颇具挑战性,旨在衡量在化学、物理和生物学领域的专业知识水平。为了进行公平比较,OpenAI 特别邀请了一批拥有博士学位的专家来解答 GPQA Diamond 的问题。测试结果显示,o1 模型的表现不仅达到了专家水平,还成为首个在这一高标准智力测试中超越人类专家的模型。
此外,模型具备强大的编程能力,在Codeforces竞赛中的表现超过了89%的人类参赛者,达到了专家大师级水平。
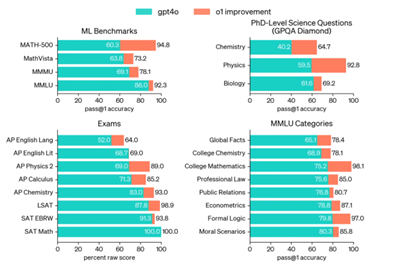
o1 在广泛的基准测试中超越了 GPT-4o
二、技术能力:o1模型通过“思维链“能力,模拟人类思维过程,并利用自我对弈强化学习技术增强推理性能
OpenAI的o1模型不仅是人工智能领域的一次飞跃,更是对人类思维逻辑的一次深刻致敬。这一模型的突破性创新在于其独有的“思维链”(Chain of Thought)能力,它能够模拟人类逐步推理的过程,将复杂的难题拆解为一系列清晰的逻辑步骤,逐步构建出解决问题的逻辑链。
在过去,大型语言模型常常因缺乏结构化推理能力而受到诟病。它们能够流畅地生成文本,却往往难以深入理解背后的复杂逻辑。这些模型,如ChatGPT和Bard,虽然能够基于大量非结构化文本数据生成看似合理的回答,但其回答往往缺乏深度,更像是随机重复的“鹦鹉学舌”(stochastic parroting),难以执行需要严密逻辑的高级推理任务。
而正如丹尼尔·卡尼曼的著作《思考,快与慢》中提到,人类大脑有两种不同的思考模式:系统一和系统二。系统一是快速、直觉性的思维方式,它包括了一些与生俱来的能力,如感知世界、集中注意力、规避风险等。而系统二则涉及更慢、更深思熟虑和分析性的思考过程,需要集中注意力,例如解决复杂的数学问题或进行重要决策。
过去,OpenAI的模型更多是进行“系统一型思维”,也就是快速、直观的决策。而o1模型通过思维链技术,让AI在回答复杂问题时能够像人类解题一样,先深入思考每一步的逻辑,然后逐步推导出最终结果,也就是模型的“系统二型思维”,且通过持续的试错和学习,使模型表现得到显著提升。就像围棋中的AlphaGo,通过不断的自我对弈,o1模型也在不断优化自己的策略和解决方案。
同时,在AI训练过程中,人工标注思维链既耗时又昂贵,而在数据量的庞大需求面前,这一任务几乎是不可完成的。o1模型采用的自我对弈强化学习(Self-Play RL)方法,让AI能够自主地通过实践和试错来学习,不再依赖于人工的每一步指导。这种自我学习和自我优化的能力,让o1模型在处理复杂任务时展现出了卓越的性能。
尽管o1技术仍处于发展初期,但它在安全性方面的表现良好。通过增强模型的深入推理能力,o1模型不仅提高了对抗攻击的鲁棒性,还降低了幻觉现象的风险,这在安全性评估中已经取得了积极的效果。
三、趋势解读:o1模型发布,开启“后训练”时代推理模型新范式
趋势1: Scaling Law之后,强化学习将突破数据限制成为大模型进步的新驱动力,并推动计算资源更多向推理能力倾斜
在人工智能的发展中,强化学习正成为大模型进步的新驱动力,特别是在OpenAI推出o1模型之后,这一趋势愈发明显。
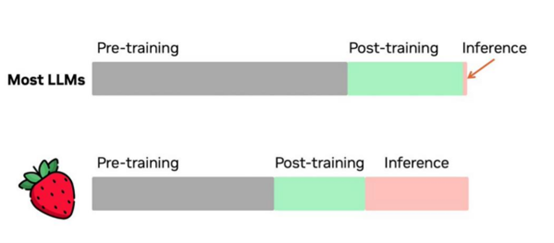
在大模型的训练过程中,预训练(Pre-training)、后训练(Post-training)和推理部署(Inference)三个阶段构成了大模型训练的完整路径。预训练阶段遵循Scaling Law,即模型性能随着参数、数据集和计算量的增加而提升。然而随着时间的推移,我们发现,即使是算力再强大,如果没有足够的高质量数据支持,模型的训练也会遇到瓶颈。因此,强化学习成为了一种新的范式,它允许模型通过自我生成的数据和自我对弈的方式来提升性能。这就好比,这个世界上数学题就这么多,如果要提升数学,可以一直生成更多的题,然后自己做题,有的做对了,有的做错了,然后去学习哪些做对了,哪些做错了,从而持续提升,这个本质上就是强化学习的过程。
在后训练阶段,模型不仅仅是在处理数据,更是在通过自我博弈和强化学习来增强其推理能力。这个过程可以产生大量新的、带有标注的数据,从而缓解了数据瓶颈的问题。同时,随着模型在推理环节的能力增强,数据的角色正在发生变化,它不再是静态的输入,而成为可以动态变化和优化的变量。这意味着AI系统能够通过用户的反馈和互动来学习和适应,提供更加个性化和优化的服务。
此外,强化学习的应用也意味着我们可以将更多的计算资源投入到推理阶段,使得模型在处理复杂任务时能够展现出更强的能力。这种趋势预示着未来AI将能够在更多细分领域中发挥重要作用,同时也为我们提供了一种新的视角来看待数据和模型训练的关系。随着技术的不断进步,我们可以期待AI在各个领域的应用将变得更加广泛和深入。
趋势2:推理能力的强化意味着推理成本的增加,反映在产品上是等待时间延长、单价提高和模型性能更强
推理能力的强化已成为AI发展的一个重要趋势,在为模型带来更强大性能的同时,也意味着推理成本的相应增加。在产品层面,则表现为用户等待时间的延长、服务的单价上涨,以及模型性能的显著提升。
在这一背景下,也就不难理解为什么OpenAI此次发布的两个模型差异化的定价和用量策略了。例如,OpenAI o1-preview模型限制用户每周使用30次,而o1-mini模型则提供每周50次的使用限额,这一定程度上是对推理成本增加的直接反映。推理环节的算力消耗巨大,这直接导致了API服务价格的上涨。为了控制成本,大模型服务提供商可能会对用户的使用次数进行限制,这可能导致普通用户需要为高质量的推理服务支付更高的费用。
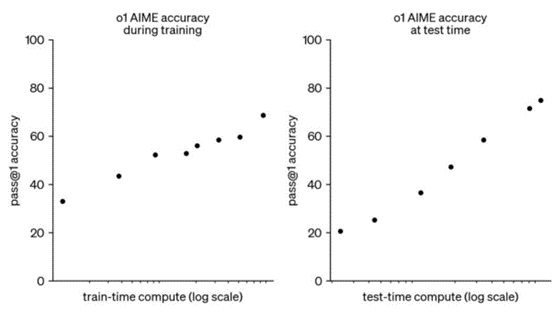
随着训练时计算和测试时计算增加,o1 的性能不断提升
随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算), o1 的性能也在不断提升。不仅提升了用户体验,也可能成为突破数据瓶颈的关键因素。新一代模型在提供答案前会进行深入的思考,如果答案不正确,它们会重新评估并给出更准确的回答。这种对准确性的重视,既体现为对速度一定程度上的牺牲,也展现了AI在推理环节的巨大潜力。
而这种对推理能力的关注预示着大模型行业可能会出现新的规律:给予模型更多的思考时间,可能会得到更优质的答案。这一现象可以概括为“模型变慢了、也变强了、也变贵了”。这种变化意味着模型在需要复杂计算的场景中,如医学诊断、金融分析、法律研究等领域,将能够发挥更大的价值,为用户提供更深入的洞察和更高质量的解决方案。
趋势3:多模态融合和长上下文理解将成为模型核心能力,随着模型能力增强,市场将涌现出更多创新应用
在大模型时代,产品逻辑已与互联网产品的传统逻辑大相径庭,模型的能力直接决定了产品的体验和质量。如果模型无法达到预期的性能,那么产品的功能和用户体验也将无法得到充分保障。因此,模型与产品的紧密结合成为了当前技术发展的一个重要趋势,模型即是产品本身。
未来的AI将不再局限于处理单一类型的数据,而是能够融合多种模态,如文本、图像和声音,更全面地理解和响应人类的复杂指令和需求,这种多模态融合技术将极大地提升AI的交互能力和应用范围。同时,随着AI对上下文的理解能力的提升,它将能够进行更复杂的推理和规划,执行更长时间的任务,并在不同模态之间进行流畅切换。这种上下文理解与推理能力的提升,将使AI在执行复杂任务时更加得心应手。
随着模型能力的不断增强,我们可以预见,市场上将出现更多基于AI的应用。AI技术的潜力将得到进一步的挖掘,如果能够持续提升其处理复杂任务的能力,AI将能够在各个领域发挥更大的作用,不仅将推动AI技术的发展,也将为用户带来更加丰富和高效的服务体验。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}